Est-ce que ça vous est déjà arrivé de vous dire :
"Si seulement je faisais des sauvegardes"
ou
"Heureusement que j'ai fais des sauvegardes"
Si vous avez connu ou connaissez toujours la première situation, cet article est fait pour vous.
Peut-être vous ne savez pas comment faire, quelle stratégie adopter ou quel outil utiliser.
Dans cet article je vais vous présenter les 3 types de sauvegarde connus, comment ils fonctionnent, comment les réaliser/ mettre en place et quel outil sont à disposition pour le faire.
La sauvegarde complète
La sauvegarde complète, c'est la plus simple, vous sauvegardez la totalité d'un dossier ou d'un système de fichier.
Vous vous en doutez, si votre disque ou dossier fais 500Go, il faudra sauvegarder les 500Go à chaque fois ce qui est peut-être plus ou moins long ; surtout si vous utilisez un cloud ou un serveur distant pour sauvegarder tout ça.
Déjà, il y a la limite de stockage qui peut vous limiter, ou une bande passante limitée, une sauvegarde journalière ou hebdomadaire sera compliqué.
Heureusement il reste 2 autres types de sauvegarde que je vais vous présenter.
La sauvegarde incrémentielle
Une sauvegarde incrémentielle commence par une sauvegarde complète et se basera ensuite sur la sauvegarde précédente pour comparer les fichiers à sauvegarder (vérifier si un fichier à été modifié/créé).
Par exemple (pour une sauvegarde journalière) :
Le lundi, on effectue une sauvegarde complète (ça sera la seule et unique sauvegarde complète).
Le mardi, on effectue une sauvegarde et comme dit plus haut, une sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, donc on utilisera la sauvegarde de lundi (qui est la sauvegarde complète) pour comparer les fichiers qu'on envoie, et la sauvegarde du mardi sera constitué seulement des fichiers qui on été modifiés ou créés depuis la dernière sauvegarde.
Le mercredi, on se base toujours sur la dernière sauvegarde effectuée, cette fois ci on compare alors la sauvegarde de mardi.
Et ainsi de suite...
Petit point important sur cette sauvegarde, si vous avez bien suivi, et je suis sûr que c'est le cas, vous êtes sûrement dit :
Mais attend, si la sauvegarde incrémentielle se base sur la sauvegarde précédente pour comparer les fichiers, si dans la sauvegarde du mardi, on a seulement 3-4 fichiers, la sauvegarde du mercredi va contenir tous les fichiers qu'on envoie SAUF les fichiers déjà présents dans la sauvegarde du mardi (ci ces fichiers n'ont pas étaient modifié).
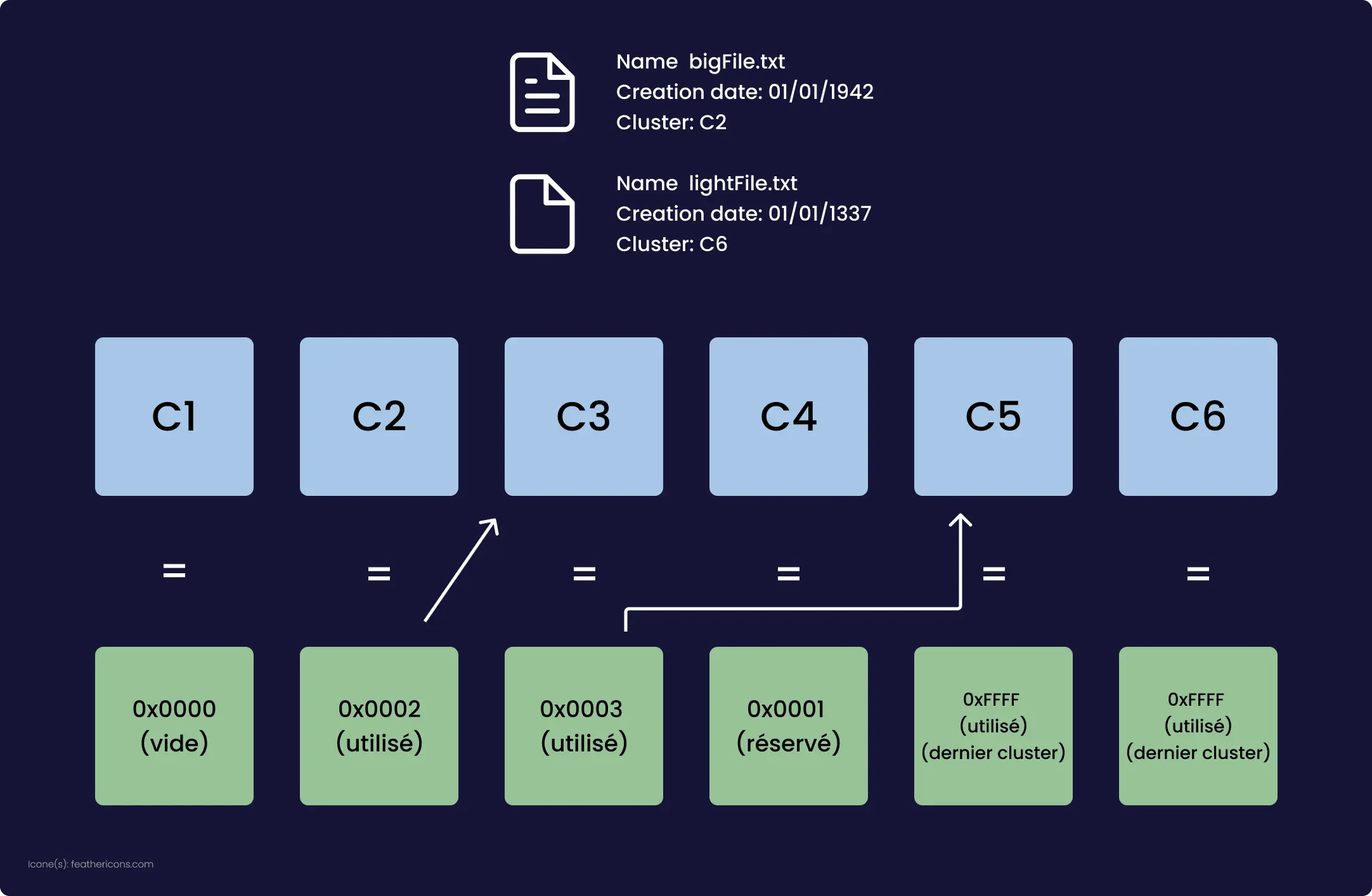
Et vous avez raison ! Pour les 3 du fond qui n'ont pas compris ou qui ne se sont pas posé cette question, un schéma vaut mieux que 1000 mots :
Imaginons, nous sommes lundi et je compte sauvegarder mon dossier personnel qui contient ces fichiers-ci :
/home/ownesis/:
- password.txt.gpg
- fat.md
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
Je sauvegarde tout ça dans /media/usb/backup_lundi (C'est la première sauvegarde, sauvegarde complète).
/media/usb/backup_lundi contient alors exactement tous les fichiers contenus dans /home/ownesis/.
Le mardi, je modifie fat.md, et crée le fichier backup.md.
De ce fait lors de la sauvegarde, seul ces deux fichiers cités plus haut seront sauvegardés dans /media/usb/backup_mardi.
/media/usb/backup_mardi:
- fat.md
- backup.md
Vient maintenant le mercredi, je modifie le fichier backup.md.
Lors de la sauvegarde, il va donc comparer mon /home/ownesis/ actuel avec /media/usb/backup_mardi/.
Et là, c'est le drame ! Dans /home/ownesis j'ai des fichiers qu'il n'y a pas dans /media/usb/backup_mardi, du coup, il va les sauvegarder, pareil pour les fichiers backup.md que j'ai modifié, il n'y a que fat.md qui lui a été inchangé qui ne sera pas dans /media/usb/backup_mercredi, et ça sera ce scénario pour toutes les sauvegardes suivantes, un jour sur deux il y aura seulement 2-3 fichiers et le lendemain tout le dossier sauf ces 2-3 fichiers de Hier (s'ils sont inchangés).
/media/usb/backup_mecredi:
- password.txt.gpg
- socks.md
- 13_reasons_why_i_hate_ramle.txt
- tftp.md
- ipv4.md
- backup.md
C'est totalement chaotique comme scénario, du coup pour remédier à ce problème, il existe deux solutions :
- Copier à chaque fois les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle (mais ça risque de consommer beaucoup de place à la longue car ca reviendrait à faire une sauvegarde complète).
- Utiliser des liens physiques sur les fichiers inchangés de la sauvegarde précédente dans la sauvegarde actuelle.
Un lien physique ?
Les Liens sous Unix et Unix like.
Pour faire simple il existe 2 types de liens
- Lien physique.
- Lien symbolique.
Un lien physique, c'est le fais de faire pointer un ou plusieurs noms de fichier vers le même inode d'un fichier.
Un inode ? quèsaco ?
Pour faire très court et simple, un inode est propre à un système de fichier Linux/Unix, chaque fichier a son propre inode, c'est un numéro unique qui identifie chaque fichier du système de fichier.
Il est possible de voir l'inode d'un fichier avec la commande ls -i fichier, ou avec la commande stat fichier.
toto.txt -> inode: 69420
toto_phylink.txt -> inode: 69420
toto.txt et toto_phylink.txt pointent tous deux vers le même inode 69420, si je modifie le contenu de toto_phylink.txt je vais aussi modifier le contenu de toto.txt et inversement.
Si je supprime un des noms de fichier, cela n'entraine pas la suppression du second, si plus aucun nom est associé a un inode, le fichier et donc "supprimé".
Fun fact: lorsqu'on "supprime" un fichier sous linux avec rm, celui ci utilise l'appel système unlink (2).
Il existe aussi les liens symboliques, ils ont le même rôle, faire un "alias" mais au lieu de pointer vers l'inode, ils pointent vers le nom du fichier qui pointe vers l'inode du fichier, exactement comme ferait un "raccourci" sous Windows.
toto.txt -> inode: 69420
toto_symlink.txt -> toto.txt
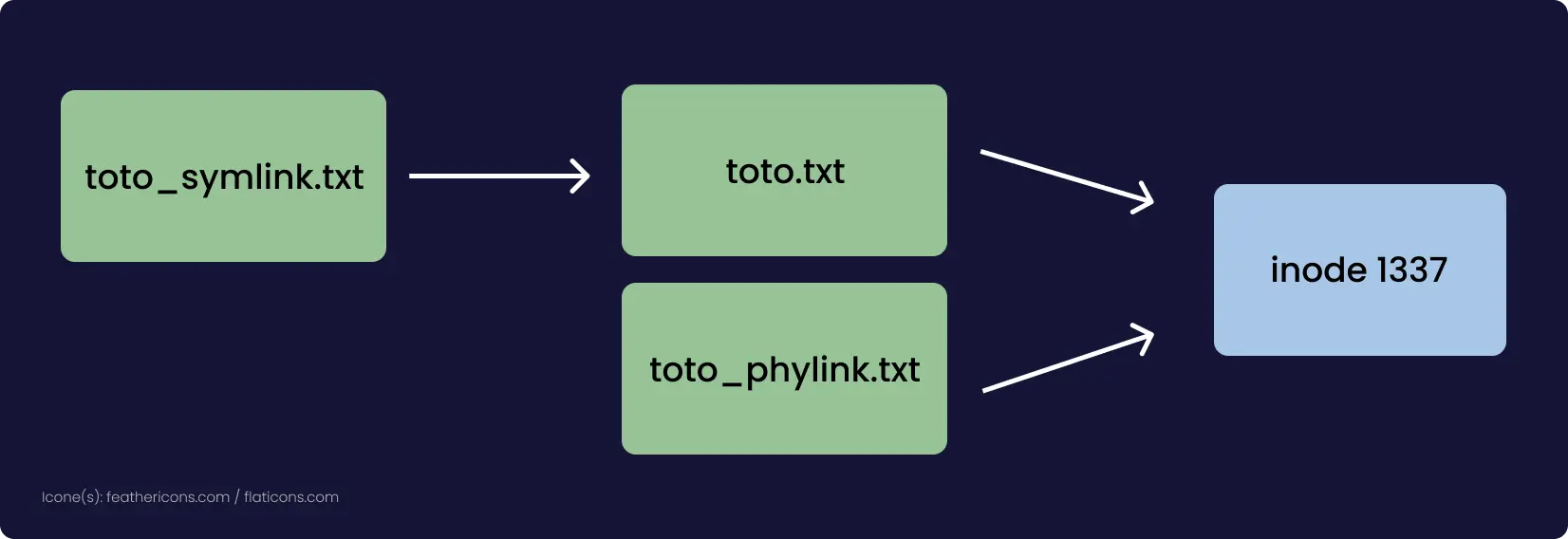
Il est possible de créer de tel lien (physique et symbolique) avec la commande ln (1).
Bon, c'est bien beau tout ça mais en quoi ça va nous aider pour la sauvegarde incrémentielle ?
Lorsqu'on comparera les fichiers actuels avec la sauvegarde précédente, au lieu de sauvegarder que les fichiers modifiés/créés, on va aussi créer des liens physiques des fichiers inchangé présent dans la précédente sauvegarde dans la sauvegarde actuelle, ce qui permettra, pour la prochaine sauvegarde, de comparer la sauvegarde précédente, mais aussi les fichiers inchangés qui précèdent cette précédente sauvegarde, etc.
Ceci va nous éviter de se retrouver dans la situation vu plus haut, car mercredi on ne comparera non plus les malheureux 2 petits fichiers de mardi avec les 7 fichiers actuels, mais les 2 fichiers + les 6 autres fichiers de la sauvegarde précédant la sauvegarde du mardi (le lundi donc).
Oui, 6 fichiers et non les 7, car le fichier fat.md est présent dans la sauvegarde de mardi.
Du coup la sauvegarde du mercredi, on se retrouve avec seulement le fichier backup.md qui a été modifié et 7 liens physiques qui pointent vers les mêmes inodes des fichiers de mardi.
Si on reprend exactement les mêmes scénarios de la sauvegarde de lundi, mardi et mercredi en employant l'astuce des liens physiques, on se retrouve avec ceci :
/media/usb/backup_lundi:
- password.txt.gpg (inode 1)
- fat.md (inode 2)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
/media/usb/backup_mardi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7) <- ici le fichier a été modifié, donc nouvel inode.
- backup.md (inode 8) <- ici, un nouveau fichier à été créé donc, nouvel inode aussi.
/media/usb/backup_mercredi:
- password.txt.gpg (inode 1)
- socks.md (inode 3)
- 13_reasons_why_i_hate_ramle.txt (inode 4)
- tftp.md (inode 5)
- ipv4.md (inode 6)
- fat.md (inode 7)
- backup.md (inode 10) <- ici, le fichier a été modifié, donc nouvel inode.
De ce fait, pour la sauvegarde de jeudi, on comparera la sauvegarde de mercredi avec les anciens fichiers qui ont toujours le même inode qui date de la sauvegarde de lundi, mais avec le fichier fat.md qui pointe vers l'inode 8 (créé dans la sauvegarde de mardi) et du fichier backup.md qui pointe vers l'inode 10 (créée dans la sauvegarde de mercredi).
Et on économise de la place, car les fichiers inchangés ne sont pas copié mais "pointé/lié" grâce aux liens physiques.
Pfiou, on en a vu des choses tout ça juste pour faire une sauvegarde incrémentielle, mais courage, c'est bientot fini.
La sauvegarde différentielle
Une sauvegarde différentielle ressemble à la sauvegarde incrémentielle, mais ne paniquez pas, elle est beaucoup plus simple à comprendre.
On commence aussi par effectuer une sauvegarde complète.
Mais contrairement à la sauvegarde incrémentielle qui compare la dernière sauvegarde effectuée, la sauvegarde différentielle elle, se comparera toujours avec la première sauvegarde (la complète).
Du coup, plus besoin de liens symboliques ou physiques vu qu'on se basera sur la même sauvegarde, on ne copiera que ce qui est nouveau ou modifié par rapport à la sauvegarde complète.
Il est quand même possible d'utiliser des liens physiques avec ce type de sauvegarde, pour que les fichiers inchangés de la première sauvegarde (sauvegarde complète) soient "lié" dans la nouvelle, mais ça reste facultatif.
Ce type de sauvegarde consomme plus de place que la sauvegarde incrémentielle, mais ça restera toujours moins que plusieurs sauvegardes complètes.
Différence entre sauvegarde différentielle et incrémentielle
Quelles sont donc leurs différences si au final, avec l'incrémentielle et les liens physiques, on se met à comparer la totalité d'une sauvegarde (comme la différentielle) ?
La seule différence, c'est que la différentielle se basera toujours sur la première sauvegarde complète et l'incrémentielle sur la sauvegarde précedente.
Ce qui veux dire que dans le cas d'une différentielle, si on crée ou modifie un fichier, que ce soit le mardi, mercredi ou autres jours, ces fichiers seront toujours copiés (même si inchangé par la suite), car ils ne sont pas présents où sont différents par rapport à la première sauvegarde.
Tandis que l'incrémentielle, les fichiers seront créer une fois et s'ils ne changent pas, lors de la prochaine sauvegarde, ils ne seront pas copiés mais "liés", car je le répète, l'incrémentielle se basera sur la dernière sauvegarde et non pas la première.
Outils mis à disposition
rsync, le meilleur outil de sauvegarde (selon moi), bon, il faut aimer la ligne de commande, RTFM et faire des scripts, mais si tout cela ne vous fait pas peur, je ne peux que vous le conseiller.
Vous pouvez utiliser l'option --compare-dest=REP pour de la sauvegarde différentielle, en comparant votre sauvegarde complète REP.
Ou l'option --link-dest=REP pour de la sauvegarde incrémentielle, il créera les liens physique tout seul en comparant le dossier REP.
Duplicati, je ne l'ai personnellement pas testé, mais j'ai vu que des bons retours dessus, il permet de faire de la sauvegarde complète et/ou incrémentielle.
borgbackup, pareille, je n'ai pas pu le tester (j'ai essayé, mais j'avais du mal avec son utilisation) mais il a l'air puissant il a beaucoup d'options et pareil j'ai eu de bon retours sur cet outil, il permet la sauvegarde incrémentielle et complète.
Sinon si vous êtes vieux jeu, pour de la sauvegarde complète, rien ne vaut le simple cp (1) pour de la sauvegarde local.
Voilà, c'est tout ! J'espère que vous avez apprécié cet article et que vous savez maintenant quel sont les possibles stratégies qu'on peut adopter pour gérer ces sauvegardes.
Quelques mentions honorables du scénario "j'aurais dû faire des backups..."
- Ajouter un espace en trop lors d'un
rm -rf et supprimer /var fichier.txt au lieu de /var/fichier.txt.
- Formater la mauvaise partition... aïe.
- Utiliser
find (1) pour chercher des fichiers présents dans un répertoire en adéquation avec l'option -exec shred -zvu {} \; et utiliser le chemin / au lieu de .
- Faire une option "clean" dans un Makefile, la tester et d'avoir supprimé les seuls et uniques fichiers source du projet.
Quelques mentions honorables du scénario "Heureusement je fais des backups"
- Supprimer par mégarde, la totalité de son Windows.
- Mauvaise manipulation de
git.
Sources: it-connect, rsync (1)
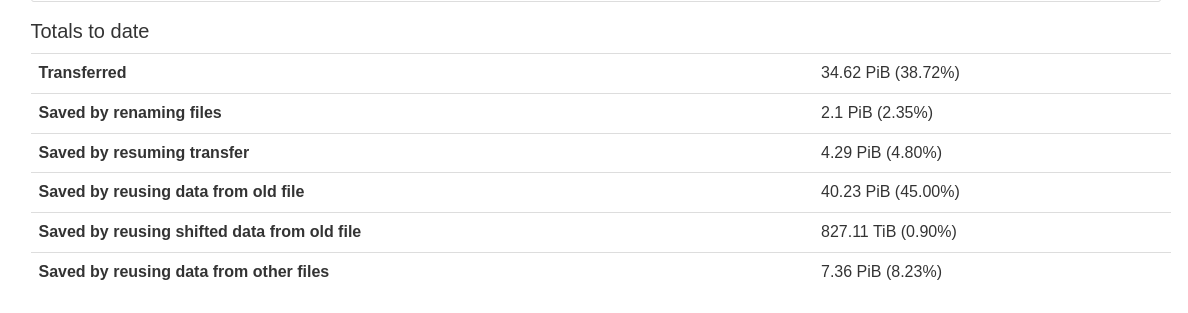
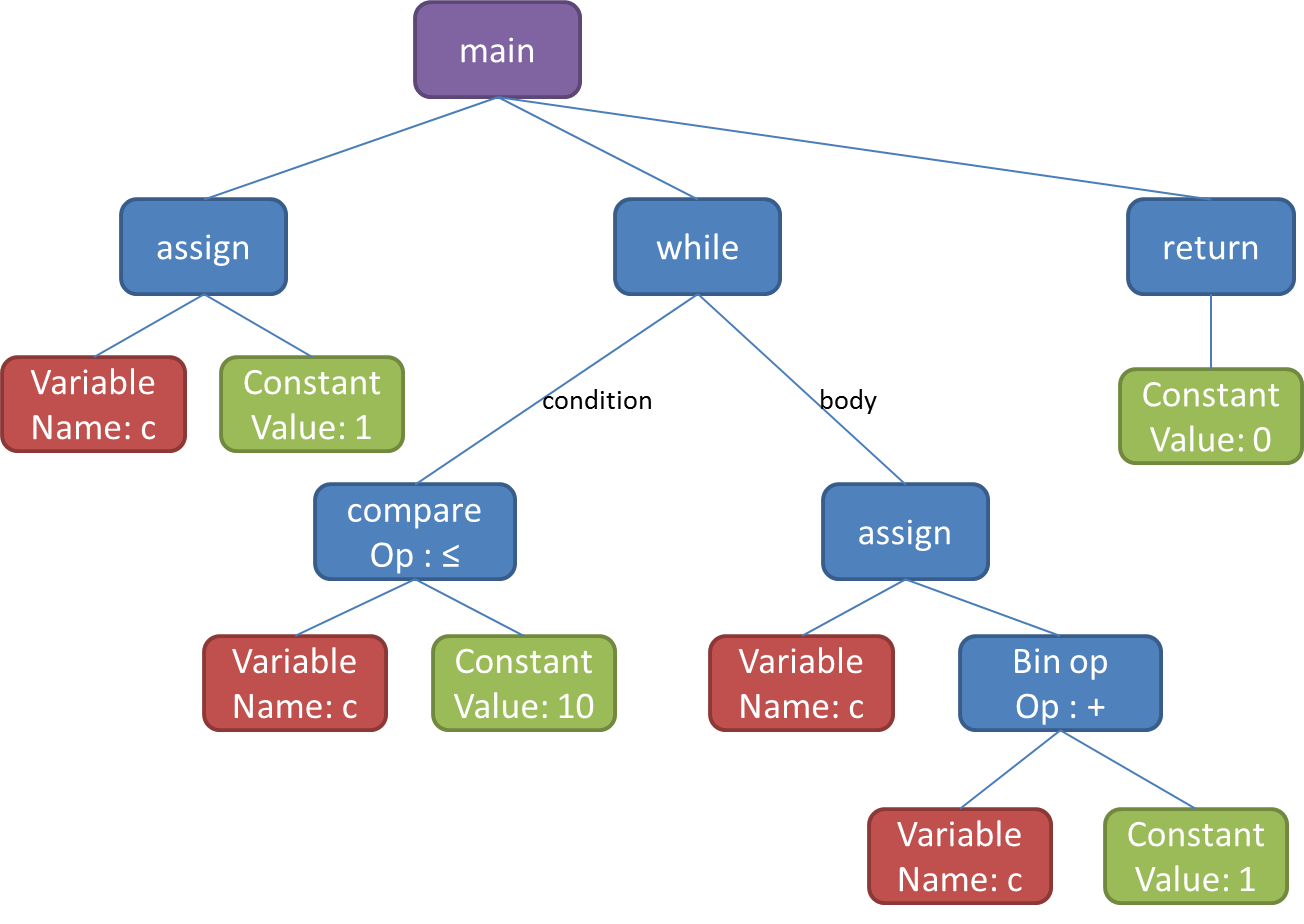




.webp)




 La seconde possibilité est d'accéder aux registres au moyen des APIs mises à disposition par Microsoft avec C/C++/C#. La dernière est l'accès avec une ligne de commande, principalement PowerShell (même si certains outils sont disponibles pour le CMD). En outre, pour naviguer au travers des différents espaces de stockage d'informations, PowerShell se base sur ce que l'on appelle des
La seconde possibilité est d'accéder aux registres au moyen des APIs mises à disposition par Microsoft avec C/C++/C#. La dernière est l'accès avec une ligne de commande, principalement PowerShell (même si certains outils sont disponibles pour le CMD). En outre, pour naviguer au travers des différents espaces de stockage d'informations, PowerShell se base sur ce que l'on appelle des 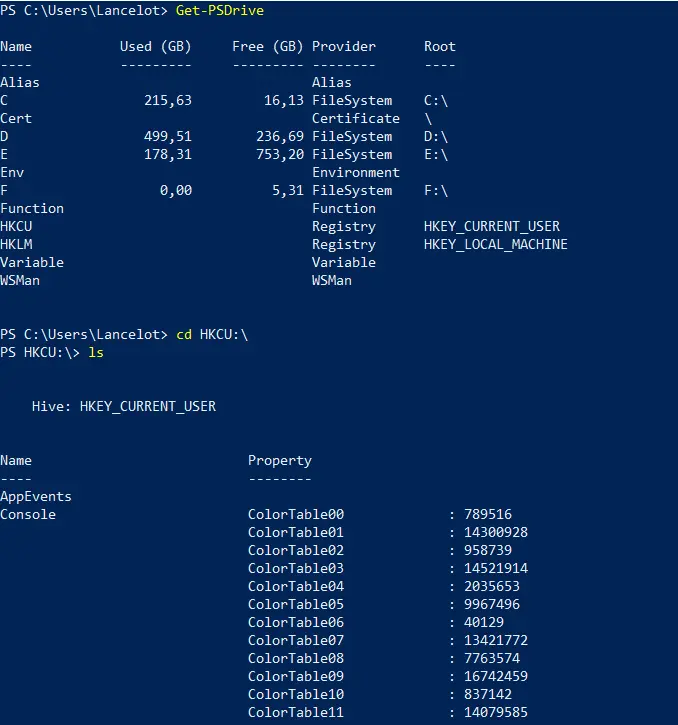 Pour savoir ce que sont
Pour savoir ce que sont 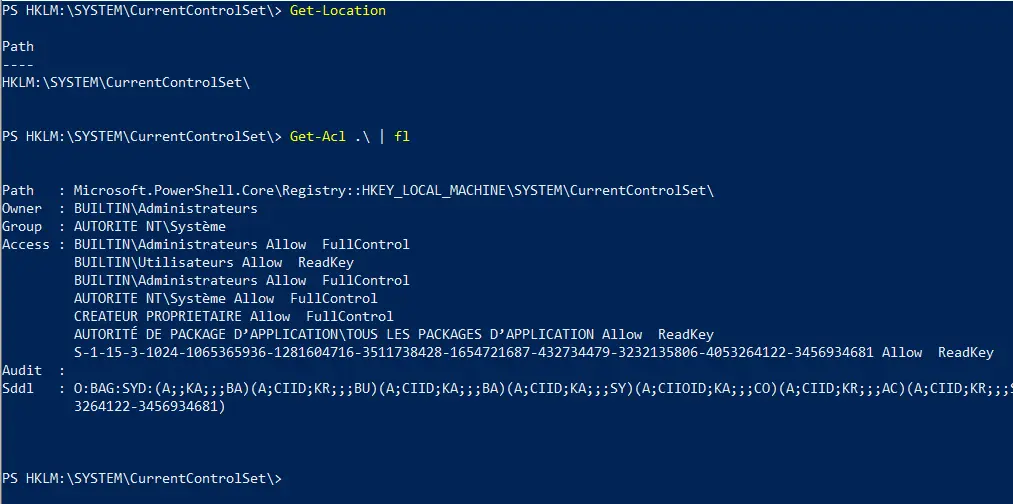
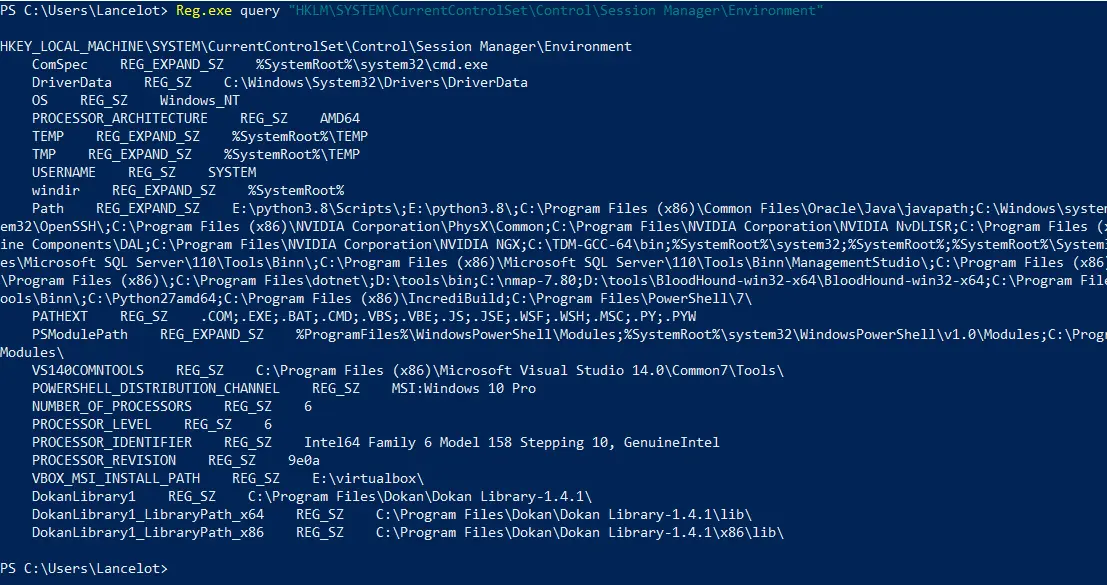 Il est également possible d'utiliser les Cmdlets natives à PowerShell, celles prédestinées à cette usage étant
Il est également possible d'utiliser les Cmdlets natives à PowerShell, celles prédestinées à cette usage étant 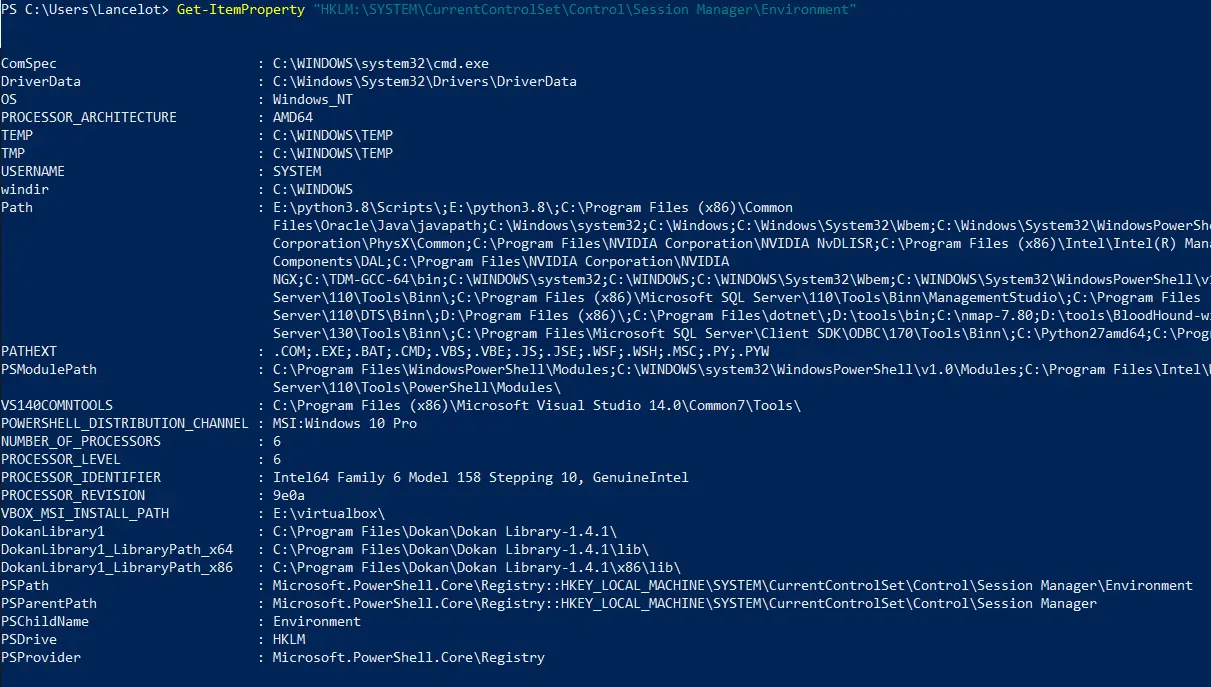 Aussi, vous pouvez vous placer dans le
Aussi, vous pouvez vous placer dans le 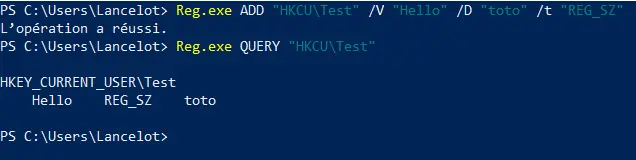 Nous pouvons faire de même avec PowerShell. En premier lieu, nous créons la clé avec
Nous pouvons faire de même avec PowerShell. En premier lieu, nous créons la clé avec 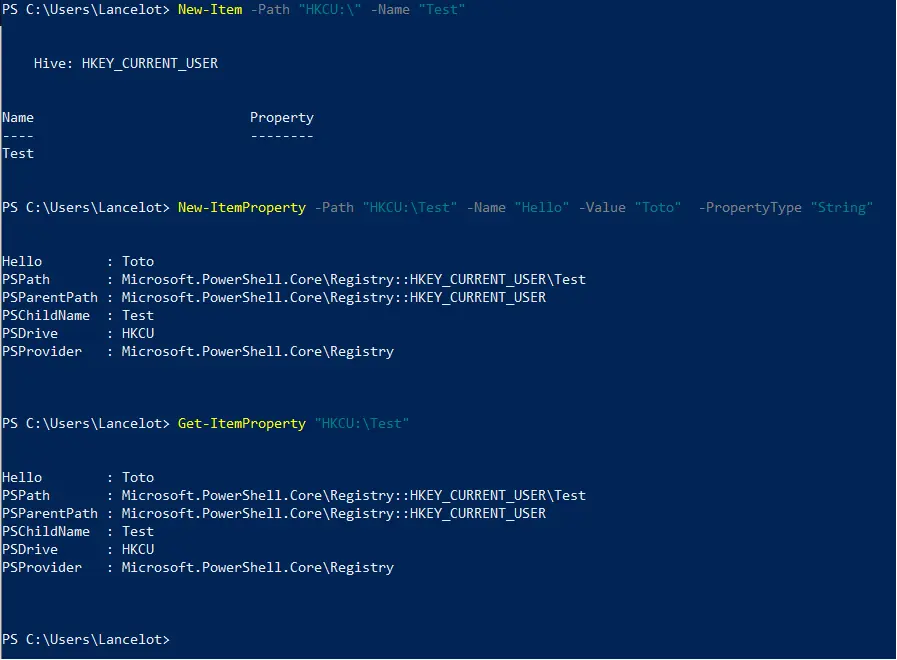 Pour modifier une clé. Avec
Pour modifier une clé. Avec 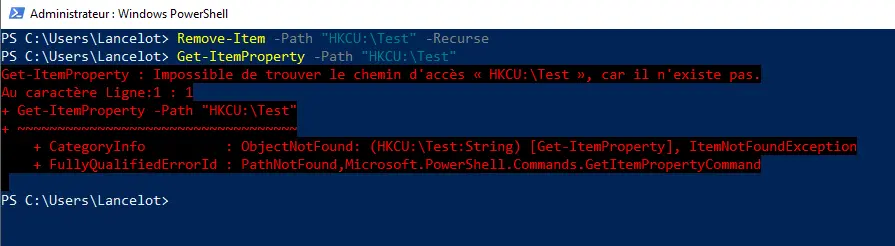 Évidemment, les exemples ici sont volontairement simplistes, et un usage bien plus avancé de ces outils est possible.
Évidemment, les exemples ici sont volontairement simplistes, et un usage bien plus avancé de ces outils est possible.
 Native daemon lance plusieurs processus dont un qui est Zygote.
Native daemon lance plusieurs processus dont un qui est Zygote.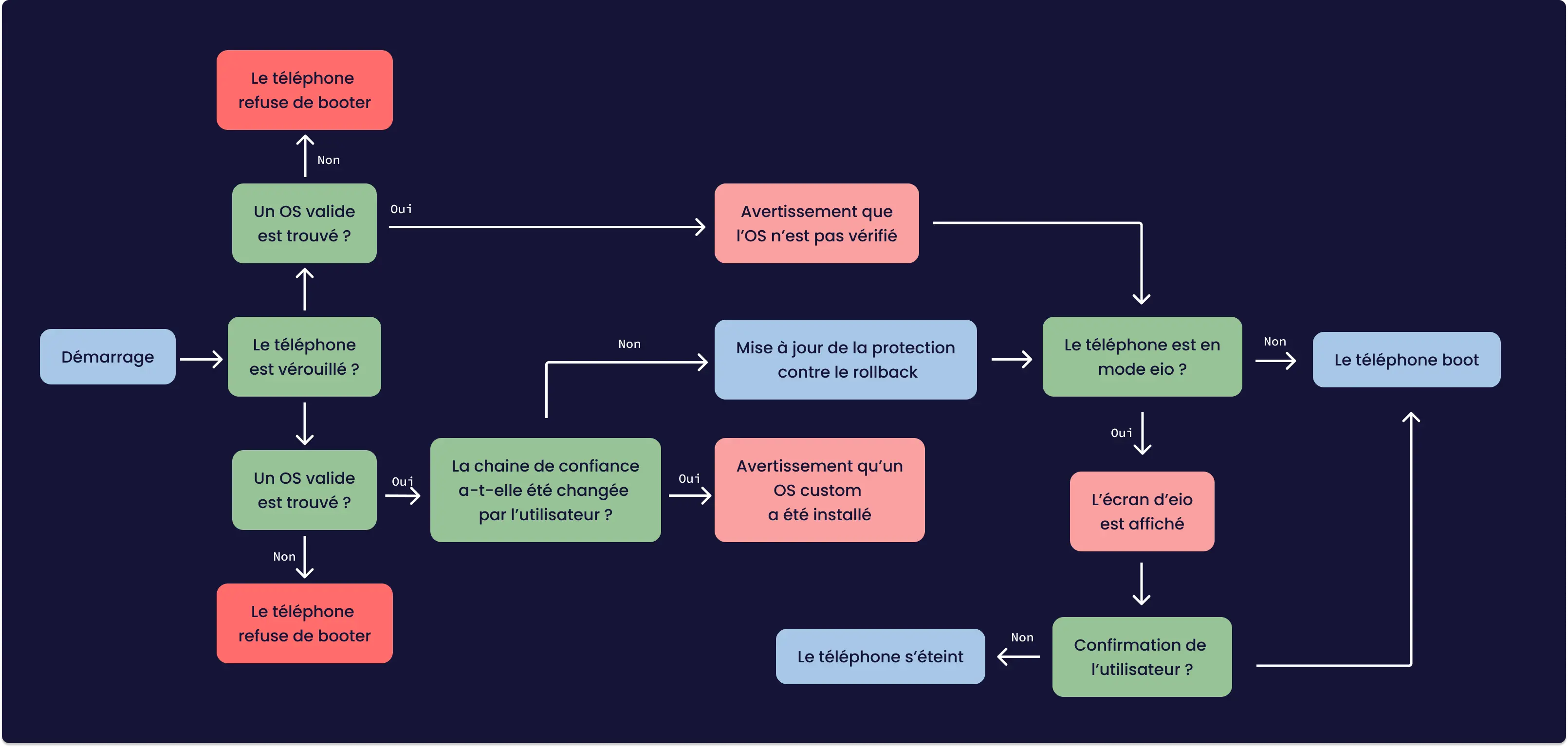
 (source :
(source : 
.webp)